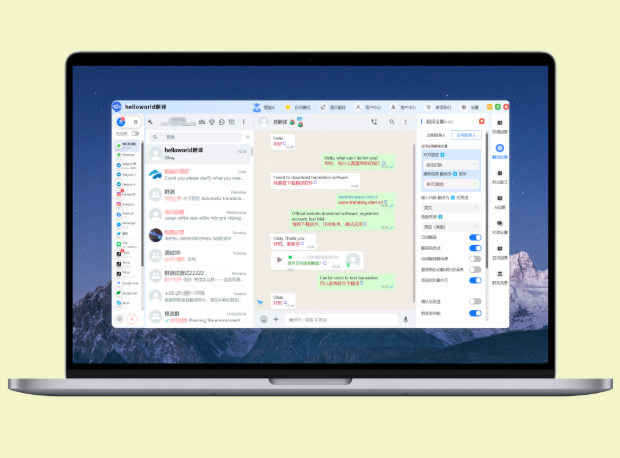
在 HelloWorld 翻译软件中,实现“一键润色”通常只需这几步:把机器翻译结果选中,点击界面上的“润色”或“智能改写”按钮,选择想要的风格(例如正式、口语、简洁或创意),确认是否启用术语库与上下文记忆,然后执行。软件会自动根据语境调整句子顺序、词汇搭配和连贯性,给出可预览的多种候选版本,用户最后确认或微调即可。如果需要批量处理、保留专有名词或应用公司风格,可以预先在设置中导入术语表和风格模板,从而实现更稳定的一键化润色效果。

先弄清“什么是一键润色”
简单来说,*一键润色*就是把机器翻译后的“直译草稿”变成更自然、更符合目标语习惯的文本,尽量减少人工逐句修饰的工作量。它不是魔法,但像一个经验丰富的同事:会调整语序、替换生硬短语、改进衔接词,并能依据你指定的风格做出不同取舍。
核心机制——怎样工作的(用通俗话说)
- 上下文理解:软件读取整段文本,不只逐句处理,避免断句导致的意思丢失。
- 风格模板:按你的选择(正式、学术、口语等)调整用词和句型复杂度。
- 术语记忆:把专有名词和常用表达锁定,防止被“润”成不该变的词。
- 候选生成:通常会生成多个版本供你挑选或做微调。
实操步骤:如何在 HelloWorld 里真正做到“一键”
下面是按顺序的操作流程,几乎适用于所有现代翻译软件的“一键润色”模块(HelloWorld 亦然):
- 1)确认初译:先用 HelloWorld 完成原文到目标语的翻译,检查是否有明显的漏译或乱码。
- 2)选择文本:在译文窗口选中需润色的段落或整篇文档。
- 3)点击“一键润色”或“智能改写”按钮(界面可能叫不同名字)。
- 4)在弹窗里设定:风格(正式/口语/简洁/学术)、语气(中性/热情/冷静)、保留词表等。
- 5)启用高级选项(可选):术语库、上下文记忆、批量处理、保留原结构等。
- 6)预览并选择候选版本,必要时进行小幅手动修改。
- 7)确认导出或同步回原文件(有的支持直接覆盖或另存为新稿)。
界面设置要点(别忽视这一步)
- 术语表导入:把公司名、产品名、专有名词做成词表导入,防止被替换。
- 风格模板保存:常用风格可保存为模板,下次直接套用。
- 批量与快捷键:为常用场景设置快捷键(一键润色整批文档)。
一个小表,帮你快速选择润色风格的预期结果
| 风格 | 典型变化 | 适用场景 |
| 正式 | 句式更完整,减少口语缩写,术语一致 | 商务信函、合同、学术论文 |
| 口语/轻松 | 用词更接地气,短句与感叹更常见 | 社交媒体、客户沟通 |
| 简洁 | 去掉冗余,直奔主题,句子更短 | 摘要、技术文档概要 |
| 创意 | 用词更丰富,句式变化大,可能加入比喻 | 广告、文案、宣传材料 |
常见问题与解决办法(边用边改的那些细节)
- 问题:专有名词被改掉怎么办?
在润色前先导入或勾选“保留术语表”,并把重要词设为不可替换;必要时把这些词用括号标注住,润色后再去除。
- 问题:润色后变得太“肤浅”或太“拗口”?
调整风格强度(有的软件允许设定“微调—中等—激进”),并选择不同候选版本,或手工在关键句做精修。
- 问题:批量文档风格不统一?
先创建并应用统一的风格模板与术语库,再进行批量一键润色。
一个简短示例(原文 → 机器译文 → 一键润色后)
| 阶段 | 示例文本(中文) |
| 原文(英文) | We will implement the feature by next quarter and ensure backward compatibility. |
| 机器译文 | 我们将在下个季度实现该功能,并确保向后兼容性。 |
| 一键润色(正式) | 我们计划于下季度完成该功能的开发,同时保证对现有系统的向后兼容。 |
提高一键润色命中率的小技巧(实用清单)
- 在开始前补充上下文说明(段落前写一句话说明用途、读者和语气)。
- 用术语表把不可替换词固定好。
- 对于关键句先人工润色一小段,保存为风格模板。
- 多用候选版本对比,别一键就接受机器第一个建议。
- 对敏感或法律性文本,润色后一定要让专业人士复核。
故障排查与备选方案
如果 HelloWorld 的一键润色效果不佳,可以先检查是否最新版本、是否联网(部分高级模型在云端运行)、术语库是否配置正确、是否启用了“保守模式”。要是本地功能受限,试试把文本分段润色或临时关闭某些预设(如“自动同义替换”)。另外,也可以把文本导出到第三方润色工具作对比,找到最适合你的组合流程。
最后,关于工作流的小建议
把一键润色作为“第一轮人工减负”的工具:它能快速把译稿变成可读草稿,省去大量重复修改,但并不能完全替代人工审校。一个靠谱的流程是:初译 → 一键润色 → 人工快速校对(重点看术语、逻辑与语气)→ 完成。这样既高效又稳妥——说到底,机器帮你把粗活做了,人来把细活收尾,效率反而更高。
好啦,就按上面那套走,边用边调,你会发现一键润色并不是黑箱,而是一套可控的工具集。哪怕第一次不完美,多保存几个模板、勤建术语表,下一次就顺手多了。