在 HelloWorld 中,翻译结果的置信度常以百分比、等级、颜色条或数值显示在译文旁或详情中;也可以在历史记录、导出报告或 API 返回的 confidence/score 字段里查看具体数值,借此判断译文可靠度并决定是否人工校对或重译。


先把问题拆成三部分:什么是置信度、HelloWorld 怎么显示它、我该如何用它
我们先像教朋友一样拆开讲清楚。置信度(confidence)其实就是系统在做出翻译时对自己“有多自信”的一个度量。HelloWorld 会把这个度量以不同方式呈现出来:用户界面上的可视化标签、详情页的数值、历史记录里的记录,以及给开发者的 API 返回字段。理解这些表现形式,能帮你在日常使用和自动化流程中更聪明地判断何时信任机器译文,何时需要人工介入。
为什么要关注置信度
- 节约时间:高置信度的译文通常不需要人工校对;低置信度译文则应该重点检查。
- 风险管理:法律、合同或医疗类文本,低置信度等于高风险,要谨慎处理。
- 流程自动化:你可以设置阈值,只有达到置信度门槛的译文才自动发布或流转下一步。
- 反馈循环:置信度信息可以用于筛选错误示例,反馈给模型以改进表现。
HelloWorld 中常见的置信度显示位置(用户界面与开发者视角)
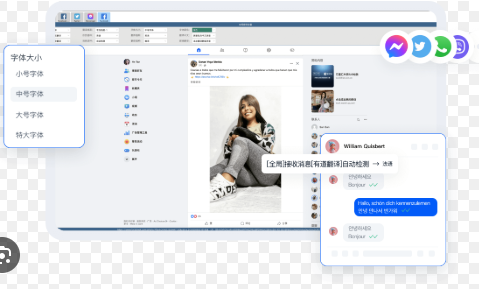
1. 译文旁的直观提示
最常见也最直观的就是:在每条译文旁直接显示一个置信度指标。形式多样:
- 百分比(例如 87%):直接告诉你机器“有多大把握”。
- 等级标签(如 高 / 中 / 低 或 A/B/C):适合快速浏览和分级。
- 颜色条或色块(绿/黄/红):视觉优先,适合移动端的速览。
- 图标提示(如盾牌、星级):简洁但有语义。
2. 结果详情页
点开某条译文的“详情”或“更多信息”时,你会看到更完整的置信度信息,包括:
- 整体置信度数值(confidence、score、probability)。
- 分词或分句的 token-level 置信度(显示哪个词或哪个部分不确定)。
- 模型说明或版本信息(哪个模型生成了该译文,便于追溯)。
3. 历史记录与批量导出
当你对大量翻译做批量处理时,HelloWorld 的历史记录或导出功能通常会包含置信度列,便于后续筛查、统计或审核。
4. API 返回字段(开发者视角)
如果你把 HelloWorld 集成到自己的系统,API 响应体通常会包含关键字段:
| 字段名 | 含义 |
| confidence / score / probability | 整体置信度数值,通常 0–1 或 0–100% |
| token_confidences / word_scores | 逐词或逐 token 的置信度数组,标示哪部分不确定 |
| model_version | 生成译文的模型或引擎版本,便于对比分析 |
| alignment / attention_info | 源词与译词间的对齐信息,可用于判断翻译是否对齐出错 |
置信度是怎么算出来的?(以最直白的方式解释)
把复杂的 AI 过程想象成一个有“直觉”和“概率盘”的翻译员。每次翻译时,模型会给每个词、每个句子的多个可能翻译打分(这个分就是概率或 Logit)。把这些分综合起来、做些校准(因为原始模型分数往往偏高或偏低),就得出一个“我有多自信”的数值,这就是置信度。
主要构成要素
- 词级概率:模型对每个输出 token 的预测概率。
- 句子级联合概率:把词级概率乘起来或用对数相加,得到句子整体概率。
- 校准(calibration):将原始概率映射到更接近真实概率的值,减少过度自信或不足自信。
- 模型集成与反馈:若使用多个模型或后端评估器,会对置信度做平均或投票。
- 语言识别与源质量校验:输入检测到错误的源语言或噪声时,会降低置信度。
如何正确解读 HelloWorld 的置信度
很多人把置信度当作“翻译一定正确或错误”的绝对判定,但其实它只是概率或模型自评。正确的思路是把置信度当作辅助决策的信号而不是终局裁判。
建议的解读方法
- 把高置信度视为“通常可靠,但仍需上下文核查”。
- 把中等置信度视为“可能需要人工快速过目或与原文比对”。
- 把低置信度视为“强烈建议人工翻译或重译”,尤其是关键信息。
- 同时看 token-level 置信度:若某些关键词置信度低,即便整体置信度高,也要重点校对那些词。
实战指南:如何在不同场景中使用置信度
场景一:日常聊天与旅游(低风险)
阈值可以较低(例如置信度 >= 60%)。快速浏览就行,遇到重要信息(地址、时间、金额)再核对。
场景二:跨境电商商品描述与客服(中等风险)
可以设置双重策略:商品描述自动通过但保留历史记录用于抽检;客服对话若涉及退款、合同条款等则需置信度高于 80% 才自动发送,低于阈值人工介入。
场景三:法律、医疗、合同等高风险文本
不建议仅凭机器翻译;将置信度作为初筛,凡低于 90% 或有关键术语置信度低的条目,都应由专业译者复核。
具体操作:在哪里查、怎么设置阈值(步骤式说明)
- 查看界面显示:打开对话或文件,注意译文旁的百分比、颜色或等级图标,点击“详情”查看 token 置信度。
- 查历史与导出:进入“历史记录”或“翻译管理”页面,导出 CSV/Excel,查找 confidence 列进行筛查。
- 调用 API:查看响应体内的 confidence、score 等字段(通常在 JSON 内)。示例字段在上表中已列出。
- 设置自动化阈值:在系统设置或企业版管理后台设置自动发布阈值(例如 >= 85% 自动发布,< 85% 标记为待校对)。
- 开启详细日志:对低置信度的条目记录源文、译文、模型版本,便于后续分析和反馈。
如何判断置信度值是否“靠谱”——检验与校准方法
模型给出的数值不一定与人类感受完全对齐,简单的检验方法能帮助你判断置信度是否可信:
- 抽样检验:随机抽取不同置信度区间(高/中/低)的译文,人工核对其真实正确率,观察置信度与真实正确率是否对齐。
- 建立映射表:把系统置信度区间映射到你业务能接受的操作,例如 90–100% = 放行、75–90% = 快速复核、0–75% = 人工翻译。
- 持续反馈:把人工复核结果回写系统,用于模型微调或置信度校准(若 HelloWorld 支持反馈学习)。
常见误区与局限(别被数字骗了)
- 误区一:置信度高就一定正确。——不对,模型可能在惯常短语上很自信,但在专有名词或新造句上出错。
- 误区二:置信度低就代表垃圾翻译。——有时候模型会因长句、罕见词或格式问题给出较低置信度,但主要信息仍可理解。
- 局限一:对于含糊或多义的源句,机器无法像人一样做出合理推断,即使置信度中等也可能误解。
- 局限二:置信度受训练数据偏差影响,不同语言对、领域、模型版本差异都会带来偏差。
举几个真实场景的例子(想法边写边整理)
例子 1:价格和数量敏感的电商文案
源文:Limited offer: 5 for $10.
如果机器把“5 for $10”翻成“五件 10 美元”或“5 美元 10 件”,意义完全不同。即便整体置信度高,也要核对数字和单位。最好检查 token-level 置信度中数字旁边的分数。
例子 2:含成语或俚语的社交文本
源文:“kick the bucket” 直接按字面翻译会错。置信度可能中等或偏低,这时更依赖模型是否识别成语。若置信度低,优先人工处理或使用短语替代库。
例子 3:技术文档里术语的一致性
对于术语较多的文本,单句置信度高并不代表术语翻译一致。需要配合术语库和历史一致性检查,结合置信度做人工抽检。
如果你是技术集成者:API 里常见的实践建议
- 总是记录 model_version(便于回溯)。
- 把 confidence 字段存到你的数据库,定期做统计分析和抽检。
- 对低置信度结果触发人工审核工作流或开启二次翻译(例如换用专业模型或人工译者)。
- 如果可能,开启 token_confidences,重点检查命名实体、数字和专有名词的置信度。
如何在 HelloWorld 里提高置信度的实际方法
- 简化输入:把复杂的长句拆成短句,减少歧义。
- 提供上下文:如果界面支持上下文(全文或前后句),把它提供给模型。
- 固定术语表:导入企业术语表或术语对照,确保关键术语的一致翻译。
- 选择合适的模型:在 HelloWorld 的模型选项里,针对不同领域选择专用模型(法律、医学、技术等)。
- 人工后编辑:对低置信度输出做人工后编辑,再把人工修正反馈给系统(如果支持)。
一些小技巧(工作中常用,便于记住)
- 把置信度分为 3 档:高(>= 90%)、中(70%–90%)、低(< 70%)。这比直接信任具体数值更实用。
- 对关键字段(数字、地址、公司名)单独做词级置信度检查。
- 把低置信度翻译自动打标签并优先进入人工队列,优化审核效率。
- 定期把抽样结果反馈给产品或数据团队,用于模型调优或阈值调整。
遇到问题怎么办?常见排查清单
- 检查是否使用了正确的源语言和目标语言设置。
- 确认是不是因为文本格式问题(换行、特殊字符、代码片段)导致置信度偏低。
- 查看模型版本,有时新旧模型在置信度计算上有差别。
- 检查是否存在术语或实体未收录在术语库中。
- 若 API 返回异常字段或缺少置信度,联系你的 HelloWorld 客服或查看文档(通常会在开发者文档中说明字段名)。
说了这么多,最后再温和提醒一句:把置信度当成“指北针”而不是“终极判官”。它告诉你去哪里查看、哪里多留心、哪里可以放心,但决策最好结合业务场景与人工经验。用得当,置信度会把机器翻译的效率和安全性都提升不少;用得不当,可能把错误放大。顺手把置信度纳入你的工作流和监控,日子会好过一点,翻译质量也会稳步上来——这就是我平常在项目里最常做的事。